Since the first instances of Apache Kafka walked the earth many moons ago, they have been tied to a core piece of underlying technology that was critical for distributed operations: Apache Zookeeper. With today’s launch of Confluent Platform 8.0, the company behind Kafka has officially excised the Hadoop-era Zookeeper from its enterprise real-time streaming platform, which will be a boom for simplicity and efficiency.
The effort to remove ZooKeeper from Apache Kafka has been going on for some time. Four years ago, Confluent CEO Jay Kreps talked about how important it was in Apache Kafka version 2.8 to replace ZooKeeper with something called KRaft, which is a combination of the Raft consensus algorithm and the Kafka log.
“It takes all the duplication between Kafka and Zookeeper, both of which were keeping a log and the fact that they have two network layers, two security models, two monitoring systems, two ways of running and configuring each of them, and it gets to just one,” Kreps said during Kafka Summit Europe in May 2021.
Intrepid companies could run open source Apache Kafka themselves in KRaft mode if they wanted to since Apache Kafka version 2.8, but it would take another four years before Confluent would offer a Zookeeper-less version of Confluent Platform, the enterprise version of Kafka for customers that want to run their own real-time streaming data platform on-prem or in the cloud.
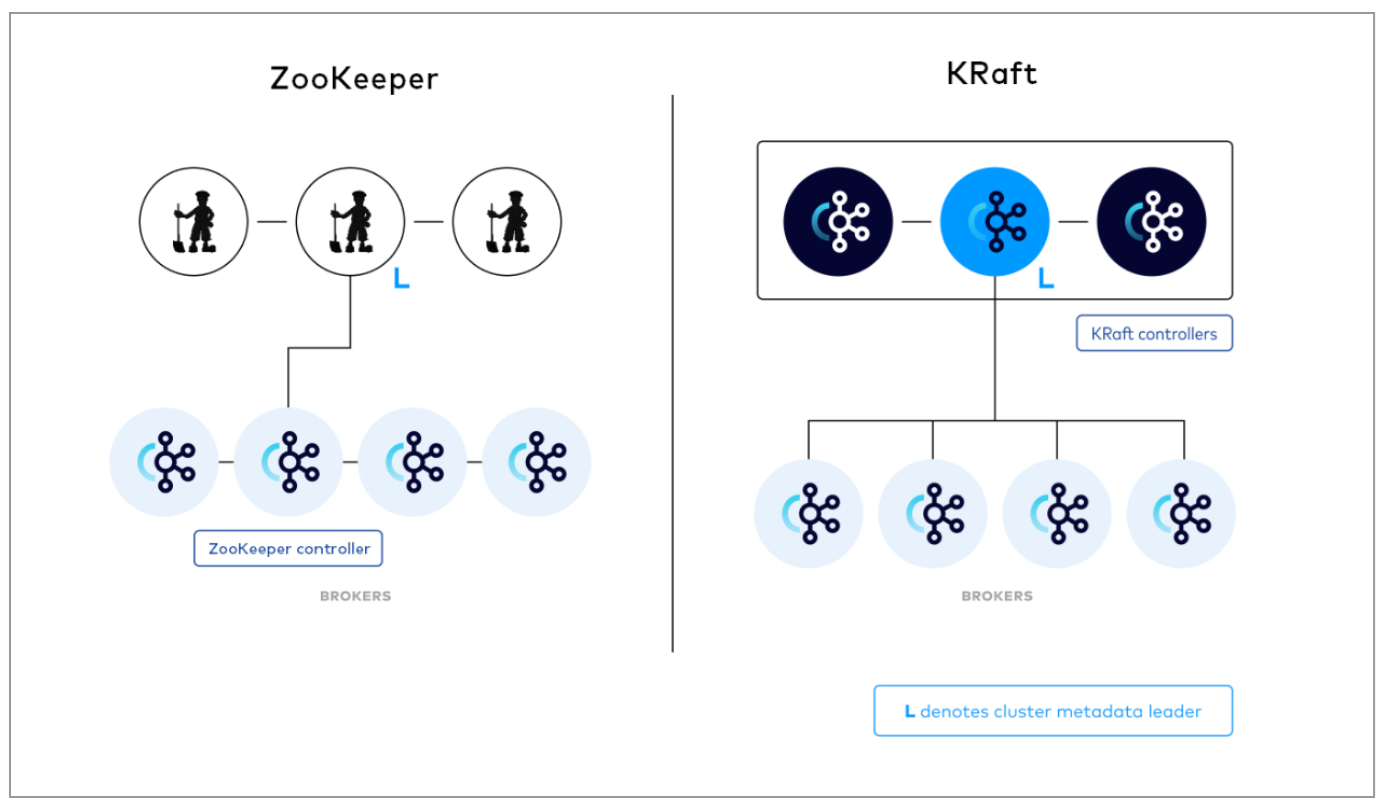
Confluent has finally replaced Apache Zookeeper with its KRaft mode in Confluent Platform 8.0 (Image courtesy Confluent)
That day finally came today with the launch of Confluent Platform 8.0. Confluent says the removal of ZooKeeper in Confluent Platform 8.0 “marks a major step forward in simplifying Kafka’s architecture and unlocking new levels of scalability and resilience.
“With the General Availability of KRaft mode, Kafka now handles its own metadata management internally, eliminating the need for a separate system with its own tools, syntax, and operational overhead,” the company says. “This streamlining allows teams to deploy and operate Kafka with fewer moving parts, faster recovery from failovers, and a unified configuration and security model across the entire platform.”
The availability of KRaft mode also brings a scalability benefit. According to Confluent, customers can now run clusters with millions of partitions. Having that many partitions will be a boon for Kafka customers, who can now essentially open more real-time data lanes that are restricted either to certain customers or certain topics.
Previously, the rule of thumb held that the maximum number of partitions a single Kafka cluster could handle was 200,000 partitions, spread across a certain number of topics, according to this post by Kafka-based streaming data company Data Streamhouse. The folks at NetApp, which run a Kafka-based data streaming services thanks to its 2022 acquisition of Instaclustr, say the maximum number of partitions they could squeeze out of a single Kafka cluster was 80,000 under ZooKeeper. With KRaft, that number soared to 1.9 million, according to NetApp. “More partitions enable higher Kafka consumer concurrency and therefore higher throughput for Kafka clusters,” NetApp wrote.
With KRaft mode now enabled by default, the failover of the metadata controller is now near-instant, Confluent says, which will reduce downtime and improve operational reliability.
“For architects and operators, this means faster performance, easier upgrades, and a foundation built for long-term growth, without the complexity of managing ZooKeeper,” write Olivia Greene, a senior product marketing manager with Confluent, and Rohit Bakhshi, a director of product management Confluent, in this blog post.
Greene and Bakhshi also touted the recent launch of a new version of the Confluent Control Center, which customers use to control Confluent Platform clusters. The company says the shift to a Prometheus-based architecture will bring big scalability enhancements. The Control Center has also adopted the Open Telemetery (OTel) standard for data collection, which will elmiiante the need for a separate cluster to house observability data.
Finally, this release brings a big security boost with the general availability of client-side field level encryption. CSFLE complements other security capabilities already supported in Confluent Platform, such as Transport Layer Security (TLS) server-side encryption and role-based access control (RBAC) with another layer of protection.
“For organizations in regulated industries such as financial services, healthcare, and the public sector, there’s often a need for even tighter data protection, especially for sensitive information like personally identifiable information (PII),” Greene and Bakhshi write. “CSFLE allows you to encrypt individual fields within messages on the producer side, ensuring that only authorized users or applications can decrypt and access data.”
Other new features Confluent is talking about in the new release include:
- Removal of compatibility for legacy clients under Apache Kafka 4.0, which Confluent Platform 8.0 is built on;
- Open preview of FlinkSQL for analyzing real-time and historical data using Apache Flink;
- Early access for queues, a new consumption model that allows multiple consumers to share partitions, process messages independently, and track delivery for queue-style workloads;
- Capability to deploy Control Center using Confluent for Kubernetes (CFK) control plane;
- Support for Ansible Core versions 2.11 with Confluent Ansible;
- A commitment to follow the Apache Kafka release cycle more closely with the community version of Confluent Platform.
Confluent will be hosting a webinar on August 8 to talk about the new features in Confluent Platform 8.0. You can register here.
Related Items:
Confluent Unifies Batch and Stream to Power Agentic AI at Scale
Ambari Hadoop Cluster Manager is Back on the Elephant
Three Takeaways from Jay Kreps’ Kafka Summit Keynote