
Today, AWS announced that Amazon Kinesis Data Streams now supports record sizes up to 10MiB – a tenfold increase from the previous limit. With this launch, you can now publish intermittent larger data payloads on your data streams while continuing to use existing Kinesis Data Streams APIs in your applications without additional effort. This launch is accompanied by a 2x increase in the maximum PutRecords request size from 5MiB to 10MiB, simplifying data pipelines and reducing operational overhead for IoT analytics, change data capture, and generative AI workloads.
In this post, we explore Amazon Kinesis Data Streams large record support, including key use cases, configuration of maximum record sizes, throttling considerations, and best practices for optimal performance.
Real world use cases
As data volumes grow and use cases evolve, we’ve seen increasing demand for supporting larger record sizes in streaming workloads. Previously, when you needed to process records larger than 1MiB, you had two options:
- Split large records into multiple smaller records in producer applications and reassemble them in consumer applications
- Store large records in Amazon Simple Storage Service (Amazon S3) and send only metadata through Kinesis Data Streams
Both these approaches are useful, but they add complexity to data pipelines, requiring additional code, increasing operational overhead, and complicating error handling and debugging, particularly when customers need to stream large records intermittently.
This enhancement improves the ease of use and reduces operational overhead for customers handling intermittent data payloads across various industries and use cases. In the IoT analytics domain, connected vehicles and industrial equipment are generating increasing volumes of sensor telemetry data, with the size of individual telemetry records occasionally exceeding the previous 1MiB limit in Kinesis. This required customers to implement complex workarounds, such as splitting large records into multiple smaller ones or storing the large records separately and only sending metadata through Kinesis. Similarly, in database change data capture (CDC) pipelines, large transaction records can be produced, especially during bulk operations or schema changes. In the machine learning and generative AI space, workflows are increasingly requiring the ingestion of larger payloads to support richer feature sets and multi-modal data types like audio and images. The increased Kinesis record size limit from 1MiB to 10MiB limits the need for these types of complex workarounds, simplifying data pipelines and reducing operational overhead for customers in IoT, CDC, and advanced analytics use cases. Customers can now more easily ingest and process these intermittent large data records using the same familiar Kinesis APIs.
How it works
To start processing larger records:
- Update your stream’s maximum record size limit (
maxRecordSize) through the AWS Console, AWS CLI, or AWS SDKs. - Continue using the same
PutRecordandPutRecordsAPIs for producers. - Continue using the same
GetRecordsorSubscribeToShardAPIs for consumers.
Your stream will be in Updating status for a few seconds before being ready to ingest larger records.
Getting started
To start processing larger records with Kinesis Data Streams, you can update the maximum record size by using the AWS Management Console, CLI or SDK.
On the AWS Management Console,
- Navigate to the Kinesis Data Streams console.
- Choose your stream and select the Configuration tab.
- Choose Edit (next to Maximum record size).
- Set your desired maximum record size (up to 10MiB).
- Save your changes.
Note: This setting only adjusts the maximum record size for this Kinesis data stream. Before increasing this limit, verify that all downstream applications can handle larger records.
Most common consumers such as Kinesis Client Library (starting with version 2.x), Amazon Data Firehose delivery to Amazon S3 and AWS Lambda support processing records larger than 1 MiB. To learn more, refer to the Amazon Kinesis Data Streams documentation for large records.
You can also update this setting using the AWS CLI:
Or using the AWS SDK:
Throttling and best practices for optimal performance
Individual shard throughput limits of 1MiB/s for writes and 2MiB/s for reads remain unchanged with support for larger record sizes. To work with large records, let’s understand how throttling works. In a stream, each shard has a throughput capacity of 1 MiB per second. To accommodate large records, each shard temporarily bursts up to 10MiB/s, eventually averaging out to 1MiB per second. To help visualize this behavior, think of each shard having a capacity tank that refills at 1MiB per second. After sending a large record (for example, a 10MiB record), the tank begins refilling immediately, allowing you to send smaller records as capacity becomes available. This capacity to support large records is continuously refilled into the stream. The rate of refilling depends on the size of the large records, the size of the baseline record, the overall traffic pattern, and your chosen partition key strategy. When you process large records, each shard continues to process baseline traffic while leveraging its burst capacity to handle these larger payloads.
To illustrate how Kinesis Data Streams handles different proportions of large records, let’s examine the results a simple test. For our test configuration, we set up a producer that sends data to an on-demand stream (defaults to 4 shards) at a rate of 50 records per second. The baseline records are 10KiB in size, while large records are 2MiB each. We conducted multiple test cases by progressively increasing the proportion of large records from 1% to 5% of the total stream traffic, along with a baseline case containing no large records. To ensure consistent testing conditions, we distributed the large records uniformly over time for example, in the 1% scenario, we sent one large record for every 100 baseline records. The following graph shows the results:
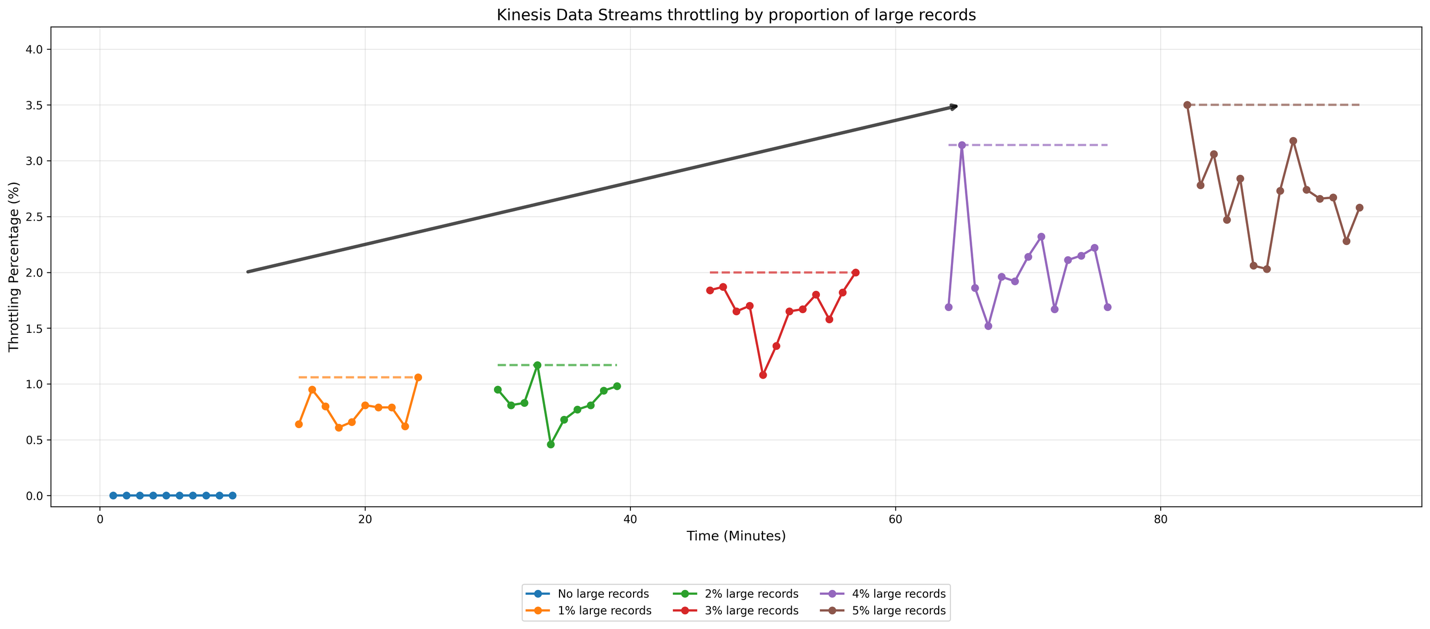
In the graph, horizontal annotations indicate throttling occurrence peaks. The baseline scenario, represented by the blue line, shows minimal throttling events. As the proportion of large records increases from 1% to 5%, we observe an increase in the rate at which your stream throttles your data, with a notable acceleration in throttling events between the 2% and 5% scenarios. This test demonstrates how Kinesis Data Streams manages increasing proportion of large records.
We recommend maintaining large records at 1-2% of your total record count for optimal performance. In production environments, actual stream behavior varies based on three key factors: the size of baseline records, the size of large records, and the frequency at which large records appear in the stream. We recommend that you test with your demand pattern to determine the specific behavior.
With on-demand streams, when the incoming traffic exceeds 500 KB/s per shard, it splits the shard within 15 minutes. The parent shard’s hash key values are redistributed evenly across child shards. Kinesis automatically scales the stream to increase the number of shards, enabling distribution of large records across a larger number of shards depending on the partition key strategy employed.
For optimal performance with large records:
- Use a random partition key strategy to distribute large records evenly across shards.
- Implement backoff and retry logic in producer applications.
- Monitor shard-level metrics to identify potential bottlenecks.
If you still need to continuously stream of large records, consider using Amazon S3 to store payloads and send only metadata references to the stream. Refer to Processing large records with Amazon Kinesis Data Streams for more information.
Conclusion
Amazon Kinesis Data Streams now supports record sizes up to 10MiB, a tenfold increase from the previous 1MiB limit. This enhancement simplifies data pipelines for IoT analytics, change data capture, and AI/ML workloads by eliminating the need for complex workarounds. You can continue using existing Kinesis Data Streams APIs without additional code changes and benefit from increased flexibility in handling intermittent large payloads.
- For optimal performance, we recommend maintaining large records at 1-2% of total record count.
- For best results with large records, implement a uniformly distributed partition key strategy to evenly distribute records across shards, include backoff and retry logic in producer applications, and monitor shard-level metrics to identify potential bottlenecks.
- Before increasing the maximum record size, verify that all downstream applications and consumers can handle larger records.
We’re excited to see how you’ll leverage this capability to build more powerful and efficient streaming applications. To learn more, visit the Amazon Kinesis Data Streams documentation.
About the authors