
Customers new to Amazon OpenSearch Service often ask how many shards their indexes need. An index is a collection of shards, and an index’s shard count can affect both indexing and search request efficiency. OpenSearch Service can take in large amounts of data, split it into smaller units called shards, and distribute those shards across a dynamically changing set of instances.
In this post, we provide some practical guidance for determining the ideal shard count for your use case.
Shards overview
A search engine has two jobs: create an index from a set of documents, and search that index to compute the best-matching documents. If your index is small enough, a single partition on a single machine can store that index. For larger document sets, in cases where a single machine isn’t large enough to hold the index, or in cases where a single machine can’t compute your search results effectively, the index can be split into partitions. These partitions are called shards in OpenSearch Service. Each document is routed to a shard that is calculated, by default, by using a hash of that document’s ID.
A shard is both a unit of storage and a unit of computation. OpenSearch Service distributes shards across nodes in your cluster to parallelize index storage and processing. If you add more nodes to an OpenSearch Service domain, it automatically rebalances the shards by moving them between the nodes. The following figure illustrates this process.
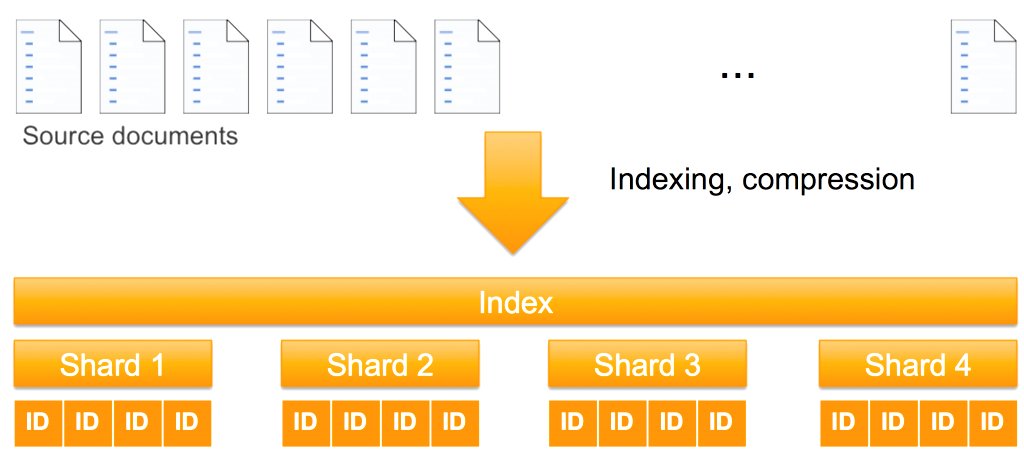
As storage, primary shards are distinct from one another. The document set in one shard doesn’t overlap the document set in other shards. This approach makes shards independent for storage.
As computational units, shards are also distinct from one another. Each shard is an instance of an Apache Lucene index that computes results on the documents it holds. Because all the shards comprise the index, they must function together to process each query and update request for that index. To process a query, OpenSearch Service routes the query to a data node for a primary or replica shard. Each node computes its response locally and the shard responses get aggregated for a final response. To process a write request (a document ingestion or an update to an existing document), OpenSearch Service routes the request to the appropriate shards—primary then replica. Because most writes are bulk requests, all shards of an index are typically used.
The two different types of shards
There are two kinds of shards in OpenSearch Service—primary and replica shards. In an OpenSearch index configuration, the primary shard count serves to partition data and the replica count is the number of full copies of the primary shards. For example, if you configure your index with 5 primary shards and 1 replica, you will have a total of 10 shards: 5 primary shards and 5 replica shards.
The primary shard receives writes first. The primary shard passes documents to the replica shards for indexing by default. OpenSearch Service’s O-series instances use segment replication. By default, OpenSearch Service waits for acknowledgment from replica shards before confirming a successful write operation to the client. Primary and replica shards provide redundant data storage, enhancing cluster resilience against node failures. In the following example, the OpenSearch Service domain has three data nodes. There are two indexes, green (darker) and blue (lighter), each of which has three shards. The primary for each shard is outlined in red. Each shard also has a single replica, shown with no outline.
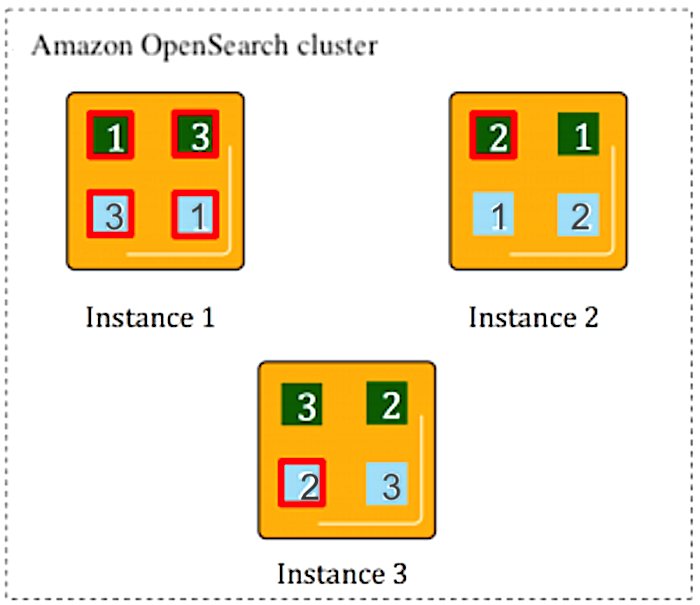
OpenSearch Service maps shards to nodes based on a number of rules. The most basic rule is that primary and replica shards are never put onto the same node. If a data node fails, OpenSearch Service automatically creates another data node and re-replicates shards from surviving nodes and redistributes them across the cluster. If primary shards fail, replica shards are promoted to primary to prevent data loss and provide continuous indexing and search operations.
So how many shards? Focus on storage first
There are three types of workloads that OpenSearch users typically maintain: search for applications, log analytics, and as a vector database. Search workloads are read-heavy and latency sensitive. They are typically tied to an application to enhance search capability and performance. A common pattern is to index the data in relational databases to give users more filtering capabilities and provide efficient full text search.
Log workloads are write-heavy and receive data continuously from applications and network devices. Typically, that data is put into a changing set of indexes, based on an indexing time period like daily or monthly depending on the use case. Instead of indexing based on time period, you can use rollover policies based on index size or document count to make sure shard sizing best practices are followed.
Vector database workloads use the OpenSearch Service k-Nearest Neighbor (k-NN) plugin to index vectors from an embedding pipeline. This enables semantic search, which measures relevance using the meaning of words rather than exactly matching the words. The embedding model from the pipeline maps multimodal data into a vector with potentially thousands of dimensions. OpenSearch Service searches across vectors to provide search results.
To determine the optimal number of shards for your workload, start with your index storage requirements. Although storage requirements can vary widely, a general guideline is to use 1:1.25 using the source data size to estimate usage. Also, compression algorithms default to performance, but can also be adjusted to reduce size. When it comes to shard sizes, consider the following based on the workload:
- Search – Divide your total storage requirement by 30 GB.
- If search latency is high, use a smaller shard size (as low as 10GB), increasing the shard count and parallelism for query processing.
- Increasing the shard count reduces the amount of work at each shard (they have fewer documents to process), but also increases the amount of networking for distributing the query and gathering the response. To balance these competing concerns, examine your average hit count. If your hit count is high, use smaller shards. If your hit count is low, use larger shards.
- Logs – Divide the storage requirement for your desired time period by 50 GB.
- If using an ISM policy with rollover, consider setting the min_size parameter to 50 GB.
- Increasing the shard count for logs workloads similarly improves parallelism. However, most queries for logs workloads have a small hit count, so query processing is light. Logs workloads work well with larger shard sizes, but shard smaller if your query workload is heavier.
- Vector – Divide your total storage requirement by 50 GB.
- Reducing shard size (as low as 10GB) can improve search latency when your vector queries are hybrid with a heavy lexical component. Conversely, increasing shard size (as high as 75GB) can improve latency when your queries are pure vector queries.
- OpenSearch provides other optimization methods for vector databases, including vector quantization and disk-based search.
- K-NN queries behave like highly filtered search queries, with low hit counts. Therefore, larger shards tend to work well. Be prepared to shard smaller when your queries are heavier.
Don’t be afraid of using a single shard
If your index contains less than the advised shard size (30 GB for search and 50 GB otherwise), we recommend that you use a single primary shard. Although it’s tempting to add more shards thinking it will improve performance, this approach can actually be counterproductive for smaller datasets because of the added networking. Each shard you add to an index distributes the processing of requests for that index across an additional node. Performance can decrease because there is overhead for distributed operations to split and combine results across nodes when a single node can do it sufficiently.
Set the shard count
When you create an OpenSearch index, you set the primary and replica counts for that index. Because you can’t dynamically change the primary shard count of an existing index, you have to make this important configuration decision before indexing your first document.
You set the shard count using the OpenSearch create index API. For example (provide your OpenSearch Service domain endpoint URL and index name):
If you have a single index workload, you only have to do this one time, when you create your index for the first time. If you have a rolling index workload, you create a new index regularly. Use the index template API to automate applying settings to all new indexes whose name matches the template. The following example sets the shard count for any index whose name has the prefix logs (provide your OpenSearch service endpoint domain URL and index template name):
Conclusion
This post outlined basic shard sizing best practices, but additional factors might influence the ideal index configuration you choose to implement in your OpenSearch Service domain.
For more information about sharding, refer to Optimize OpenSearch index shard sizes or Shard strategy. Both resources can help you better fine-tune your OpenSearch Service domain to optimize its available compute resources.
About the authors
 Tom Burns is a Senior Cloud Support Engineer at AWS and is based in the NYC area. He is a subject matter expert in Amazon OpenSearch Service and engages with customers for critical event troubleshooting and improving the supportability of the service. Outside of work, he enjoys playing with his cats, playing board games with friends, and playing competitive games online.
Tom Burns is a Senior Cloud Support Engineer at AWS and is based in the NYC area. He is a subject matter expert in Amazon OpenSearch Service and engages with customers for critical event troubleshooting and improving the supportability of the service. Outside of work, he enjoys playing with his cats, playing board games with friends, and playing competitive games online.
 Ron Miller is a Solutions Architect based out of NYC, supporting transportation and logistics customers. Ron works closely with AWS’s Data & Analytics specialist organization to promote and support OpenSearch. On the weekend, Ron is a shade tree mechanic and trains to complete triathlons.
Ron Miller is a Solutions Architect based out of NYC, supporting transportation and logistics customers. Ron works closely with AWS’s Data & Analytics specialist organization to promote and support OpenSearch. On the weekend, Ron is a shade tree mechanic and trains to complete triathlons.