
A former colleague recently asked me to explain my role at Precisely. After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.”
That got me thinking. We often use different terms when we’re talking about the same thing – in this case, “data appending” vs. “data enrichment.”
Since that conversation, I’ve talked to others in my network about their terminology. I’ve noticed that “data appending” is more commonly used in industries like marketing and telecommunications, while “data enrichment” seems to be the preferred term in financial services and retail.
While the terms may be used interchangeably, there are some nuances worth considering. In this post, we’ll cover:
- the difference between data appending and data enrichment
- common challenges – especially regarding data quality standards
- what we’re doing at Precisely to ensure you get the biggest return on your data enrichment/appending initiatives
Regardless of terminology, I hope we can all agree that in today’s data-driven world, you need to constantly seek ways to better understand your customers, markets, and operations.
To get the best results, it’s critical to add valuable information to existing records through data appending or enrichment. By adding new attributes to existing datasets, your organization unlocks deeper insights, improves decision-making, and personalizes customer experiences.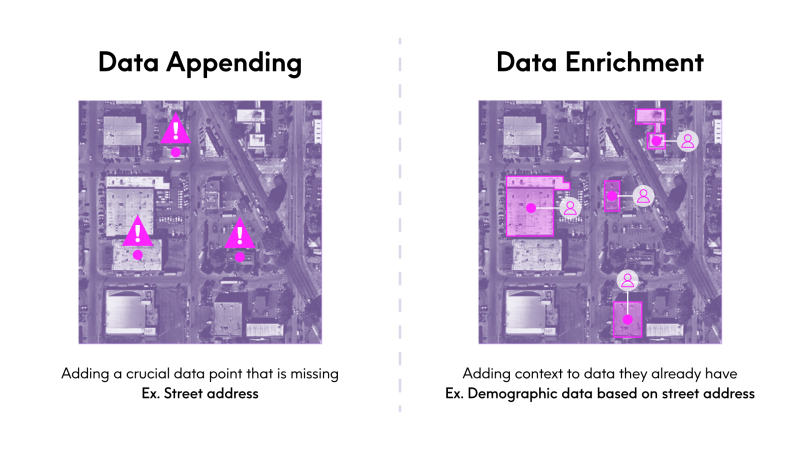
Data Appending vs. Data Enrichment: What’s the Difference?
As I mentioned, we often hear “data appending” and “data enrichment” used interchangeably, and that’s understandable given that they both serve to enhance your existing datasets with data from various sources.
However, there are some slight differences between the two that you should be aware of. Here’s a quick breakdown:
Data Appending: Filling in the Blanks
Data appending primarily focuses on adding missing data to existing records. It’s about filling in the blanks.
Use case (Retail):
As an example, imagine a retail company has a customer database with names and addresses, but many records are missing full address information.
- The solution: They use a data appending process to match their existing data with a third-party database that contains full street addresses.
- The result: They now have more complete customer records – setting them up to enrich that data with demographics information for marketing or customer service.
Essentially, the retail company is adding a crucial data point that was missing.

Data Enrichment: Adding Context for Deeper Insights
Data enrichment is the next step most organizations take after filling in data gaps through data appending. It adds contextual information to existing records to provide a deeper understanding of the topic being analyzed or acted upon.
Use case (Retail):
Let’s use the same retail company from our appending example above. After appending missing addresses, they want to better understand their customers’ purchasing habits and preferences.
- The solution: They use a data enrichment process to add demographic data (age, income, location), lifestyle data (interests, hobbies), and purchase behavior data (frequency, average spend) to their customer records.
- The result: They now have a much richer understanding of their customer base, allowing them to create targeted marketing campaigns, personalize product recommendations, and improve customer experience.
Essentially, the retail company is adding context to the customer data they already have and is now in a better position to achieve their desired outcomes.
Which one do you need?
So, what’s the final word on data appending vs. data enrichment? As you can see, both terms are certainly in the same family, but they also serve different purposes based on your desired use case.
- If you’re missing key data points, you need appending.
- If you have complete records but want richer insights, you need enrichment.
I want to note that at Precisely, we have excellent data appending and enrichment capabilities, but we use the term “data enrichment” as it encompasses our portfolio of data content products.
Within our solutions, it can describe our data appending and enrichment capabilities – for example, appending a location to a business address using our geocoding software, or adding industry code information to that same record using our Data Graph API.
The term “enrichment” simply makes more sense for us. Plus, I don’t want to open myself up to “GM of Appending” jokes …
Applying Data Appending and Enrichment
Now, with some of those nuances defined, let’s talk more about the information you might seek out for appending/enriching your internal data. This can include:
- adding basic information such as postal codes or phone numbers (appending)
- adding demographic details, firmographic attributes, behavioral data, or even location-based information to understand physical characteristics, opportunities, and risks (enrichment)
The goal is to build an accurate and comprehensive view of each record, enabling a holistic understanding of the data being used. Often, appending data improves confidence in existing information, while enriching data adds context – but also complexity. The key is finding the right balance.
A Real-World Example: Enhancing CRM Data at Precisely
At Precisely, we apply these same principles to our own operations. Our Chief Data Officer, Dave Shuman, recently walked through a data appending and enrichment project for our CRM data.
The goals of this project are to ensure accurate customer records by defining and enforcing relationships based on legal entities, consistent naming, branding, and ownership. We use this information to understand our customers’ decision-making process, opportunity size, and product fit.
Why does this matter? As an example, there is a different use case for an LLC that owns several regional restaurant franchises, versus the company that owns and manages the national brand(s) of those the restaurants – and we may sell different products to each based on their unique needs. Without data appending and enrichment, it would be difficult to tailor our approach effectively.
To get high-quality results, our team must append and enrich specific information to each record with a very high level of confidence – using accurate and up-to-date data. This is critical, and important to prioritize as you embark on your own enrichment initiatives.
With that in mind, there are several common challenges that you need to be aware of and manage along the way.
Solutions
Unlock the true potential of your data. Gain unparalleled insights about your audience, locations, risk levels, and more with rich, relevant context from additional sources.
Challenges in Ensuring Data Quality Through Appending and Enrichment
The benefits of enriching and appending additional context and information to your existing data are clear – but adding that data makes achieving and maintaining data quality a bigger task.
Several challenges arise in setting up these processes:
- Fit: Data sources vary in quality and intended use. Data is often repurposed into new uses that it wasn’t designed for. This can lead to data that isn’t fit-for-purpose, impacting the quality and completeness of results or producing inaccuracies that may not be readily apparent.
Understanding the original intent, strengths and limitations of input data is key to adding value vs. creating noise within the analysis.
- Matching accuracy: Matching records between datasets is complex. Mismatched records introduce errors where data is appended to the wrong records. Unmatched data leads to incomplete information. Both types of matching errors result in misleading or incomplete analysis.
Mapping data to improve results takes time and is very important in achieving the best results.
- Data inconsistencies: Different sources use different formats, naming conventions, and units of measurement. Resolving these inconsistencies is crucial, but often time-consuming and expensive.
- Data changes: Data creators are notorious for making uncommunicated changes to record layouts, headers, and the actual data content. Couple these with changes in release dates, and your ability to meet schedules and output goals is challenged.
Plan for the unknown and talk to your data providers about the need for proactive communications. If possible, negotiate minimum lead time for communications – we do this with our suppliers and our customers.
- Documentation: Many datasets are not accompanied by clear or up-to-date documentation. And even when there is documentation, people don’t read it. This makes de-coding the data a challenge that may prevent potentially valuable data from being usable.
Within your operations, stress the need to get and read documentation. Explore using tools like AI to identify and summarize product changes and other important information. I also recommend setting up acknowledgement practices for critical information – ensure the communicator doesn’t consider their job done until they receive acknowledgement from the person that needs to know the information.
- Data decay: Data constantly changes. People move, businesses evolve, and consumer preferences shift. Appended data can quickly become outdated. Have a plan to keep the data up to date that matches the importance of the decisions you are making with the data.
Let’s revisit the example of the internal CRM work here at Precisely.
Each of the challenges we’ve outlined requires a clear strategy – for both initial data appending, and for ongoing data management. While we’re fortunate that we can use our own products for this process, it doesn’t change the complexity involved.
Each of our input datasets needs to be carefully evaluated, and we must define specific:
- fields
- values
- transformation processes
- rules
- update frequencies
This project involves many datasets – including data from a leading firmographics supplier, our own products, and data from internal systems. Because each of these datasets is dynamic, we are designing our systems with long-term maintenance in mind. For example, we have a process for refreshing brand standardization that is a different frequency than credit score, given the differences in risk associated with those data.
The Importance of Upstream Information in Data Maintenance Planning
To maximize the impact of the appended and enriched data, you must understand what’s happening to the data before it gets to you. Make sure you have a solid understanding of the following:
- Data sources: Know where each dataset comes from. This includes knowing the origin, or where the data came from initially (e.g., directly from an internal system or application, a combination of multiple files, or a third-party supplier).
Ensure you have permission and rights to use the data before you invest time in building the processes to use the data. If you know where the data came from, you may be able to source the data before degrading transformations have occurred, improving your results and avoiding “retransforming” costs.
- Timing of updates: Know the schedule of data updates. Understand the update cycles of each source and plan accordingly. There may be sequencing dependencies for your enrichment work to achieve the best outcomes. Data that is out of sync is difficult to match and therefore challenging to append or enrich.
- Transformations: Know if there are changes made to the data upstream (e.g., cleaning, filtering, calculations, aggregations). These changes may add value to your use case, or they may reduce value. If you don’t know what transformations have been made to the data, I’d suggest you not use it.
- Data validation and verification: Regularly validate both input data and the appended/enriched data to identify and correct inaccuracies before they impact decisions. This sounds basic, but I’m always surprised by how often ongoing checks are not put into place.
- Source monitoring: Track the reliability and update methods of data sources to prioritize high-quality data and avoid outdated or circular information.
- Budget: There is a cost for carrying data. Plan for it. This includes license costs, access to internal systems that may fall into another department’s budget (and could be cut without your input), cloud costs, and staffing. Plan for this with your eyes wide open and ensure you have a voice in internal access decisions before you become reliant on the data.
Supplier Scorecards Are a Powerful Tool
I’ve found that upstream coordination can greatly reduce the carrying costs over time. At Precisely, we have developed a supplier scorecard that we use to evaluate suppliers over time.
We share this information with our suppliers to help them prioritize improvements and understand the impact they have on downstream schedules and quality.
These statements are clear and direct – we don’t sugarcoat feedback, because these evaluations are essential for suppliers to add value by reducing our costs and complexity. We are beginning to do this for internal data sources as well.
Because the scoring is objective, and the scorecards are standardized, we compare suppliers to one another. We have found that suppliers like to know where they rank overall in our assessment, and we can set targets for their improvement. We also thank our “top suppliers” for their best practices.

Leveraging Record IDs to Improve Efficiency and Quality in Data Enrichment and Appending
Unique and persistent record identifiers (IDs) are essential to streamlining your data enrichment and appending initiatives and improving quality.
Persistent IDs provide a consistent link between records across your datasets, simplifying matching and reducing the complexity of dataset integration operations.
Here at Precisely, the use of IDs is an important component of operational efficiency gains we’ve made over time. We use them internally in our back-office systems for:
- managing customer and supplier information
- communicating with our various data suppliers
- creating the products we sell – and ensuring that these various products are in sync with each other so that customers can confidently use them for both appending and enrichment
This isn’t just theory. We are increasingly using IDs with outside suppliers to reduce cycle time and improve data quality.
Most recently, we announced the launch of Data Link: an ecosystem of pre-linked datasets from leading data providers. This is a groundbreaking partner program that streamlines historically complex enrichment processes, helping you reduce overhead, accelerate time to value, and boost overall ROI.
Data Link leverages unique IDs to connect datasets, minimizing time and resources spent on onboarding and integrating new data. Precisely customers can use this linkage to access and connect their data to any of our partner datasets, and organizations that are customers of our partners can connect their data to any Precisely dataset with ease.
GeoX, for example, is one of our great Data Link partners, and we’re working with them on some very complex data workflows. By connecting our datasets with GeoX’s data via IDs, we streamline intake and production processes, enhance communication, improve quality management, and ultimately serve our joint customers more effectively.
Admittedly, there was a lot of time and investment in enabling the ID systems we are using – ranging from understanding and developing specifications to legal agreements between companies. But experience shows this investment is worth the effort and that the ROI is quickly achieved.
We’re thrilled to be building partnerships like these that help businesses like yours streamline enrichment/appending processes and reach time-to-value faster. And, we’re just getting started – we’ll be expanding our Data Link program with more partners soon.
Get Higher ROI from Your Enrichment/Appending Initiatives
Precisely offers comprehensive data enrichment solutions to maximize your ROI:
- Unparalleled data quality: Access our portfolio of reliable, interconnected, and up-to-date datasets.
- Advanced matching and linking: Minimize matching errors and ensure data integrity.
- Seamless data integration, appending and enrichment: Streamline the appending and enrichment processes and simplify data quality management by delivering data and software that work together—and by expanding the datasets that are linked by IDs.
- Tailored solutions and expertise: We work closely with our partners and clients to develop customized solutions and provide expert guidance.
By leveraging our data enrichment solutions, you unlock the full potential of your address data – driving better decisions, improving operational efficiency, and achieving a higher ROI.
Whether you’re a financial services company that needs to improve risk assessment accuracy, or a retailer that must boost targeted advertising campaign performance, you can be sure that you’ll have the capabilities you need to meet your objectives.
Final Thoughts
Both data enrichment and data appending offer tremendous value, but maintaining data quality is key to success.
By understanding the nuances and challenges, planning for ongoing maintenance, and leveraging tools like record IDs and Precisely solutions, you’ll unlock the true power of your data and drive better business outcomes.
To learn more, don’t hesitate to reach out, or check out the latest on our enrichment solutions – including Data Link, a groundbreaking ecosystem of pre-linked datasets from leading data providers.