
As organizations increasingly adopt Apache Iceberg tables for their data lake architectures on Amazon Web Services (AWS), maintaining these tables becomes crucial for long-term success. Without proper maintenance, Iceberg tables can face several challenges: degraded query performance, unnecessary retention of old data that should be removed, and a decline in storage cost efficiency. These issues can significantly impact the effectiveness and economics of your data lake. Regular table maintenance operations help ensure your Iceberg tables remain high performing, compliant with data retention policies, and cost-effective for production workloads. To help you manage your Iceberg tables at scale, AWS Glue automated those Iceberg table maintenance operations: compaction with sort and z-order and snapshots expiration and orphan data management. After the launch of the feature, many customers have enabled automated table optimization through AWS Glue Data Catalog to reduce operational burden.
The Amazon SageMaker lakehouse architecture now automates optimization of Iceberg tables stored in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and improving query performance. Previously, optimizing Iceberg tables in AWS Glue Data Catalog required updating configurations for each table individually. Now, you can enable automatic optimization for new Iceberg tables with one-time Data Catalog configuration. Once enabled, for any new table or updated table, Data Catalog continuously optimizes tables by compacting small files, removing snapshots, and unreferenced files that are no longer needed.
This post demonstrates an end-to-end flow to enable catalog level table optimization setting.
Prerequisites
The following prerequisites are required to use the new catalog-level table optimizations:
Enable table optimizations at the catalog level
The data lake administrator can enable the catalog-level table optimization on the AWS Lake Formation console. Complete the following steps:
- On the AWS Lake Formation console, choose Catalogs in the navigation pane.
- Select the catalog to be enabled with catalog-level table optimizations.
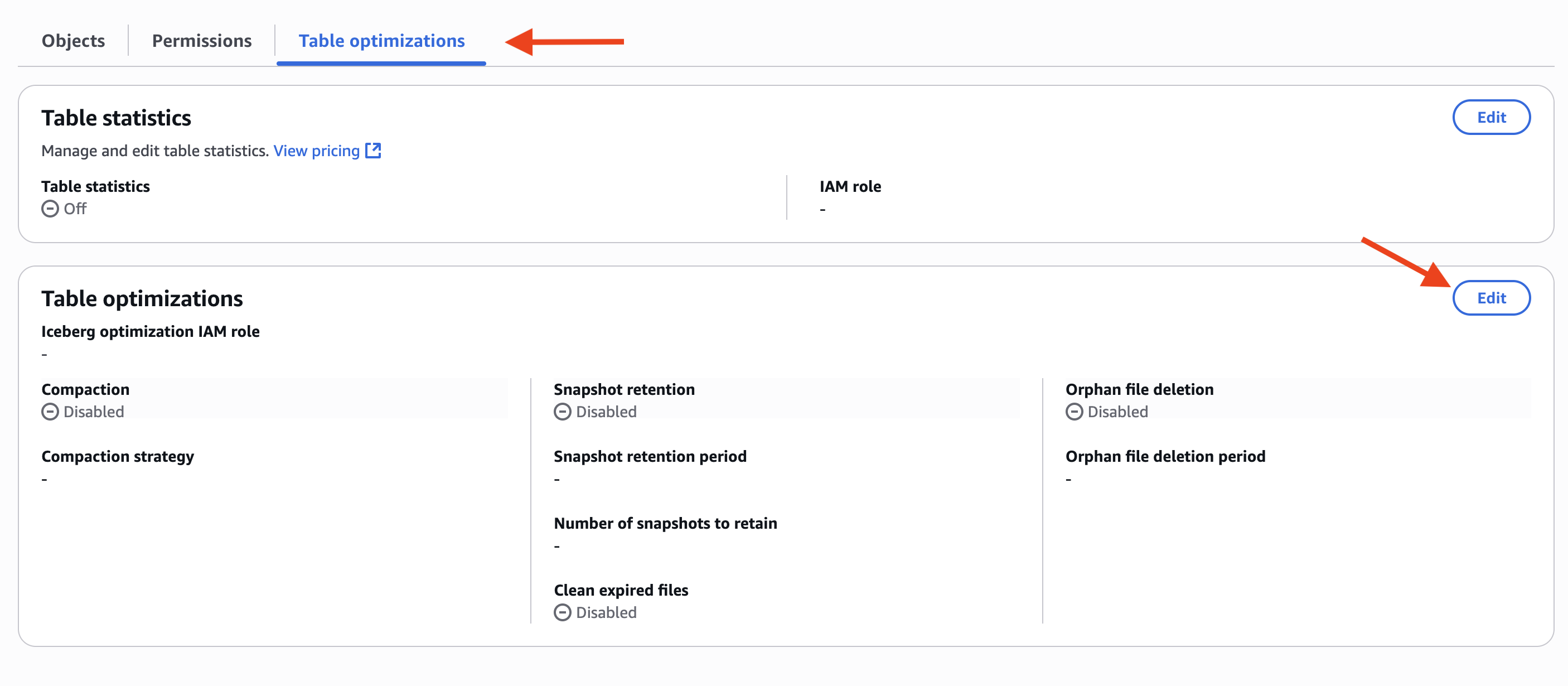
- Choose Table optimizations tab, and choose Edit in Table optimizations, as shown in the following screenshot.
- In Optimization options, select Compaction, Snapshot retention, and Orphan file deletion, as shown in the following screenshot.
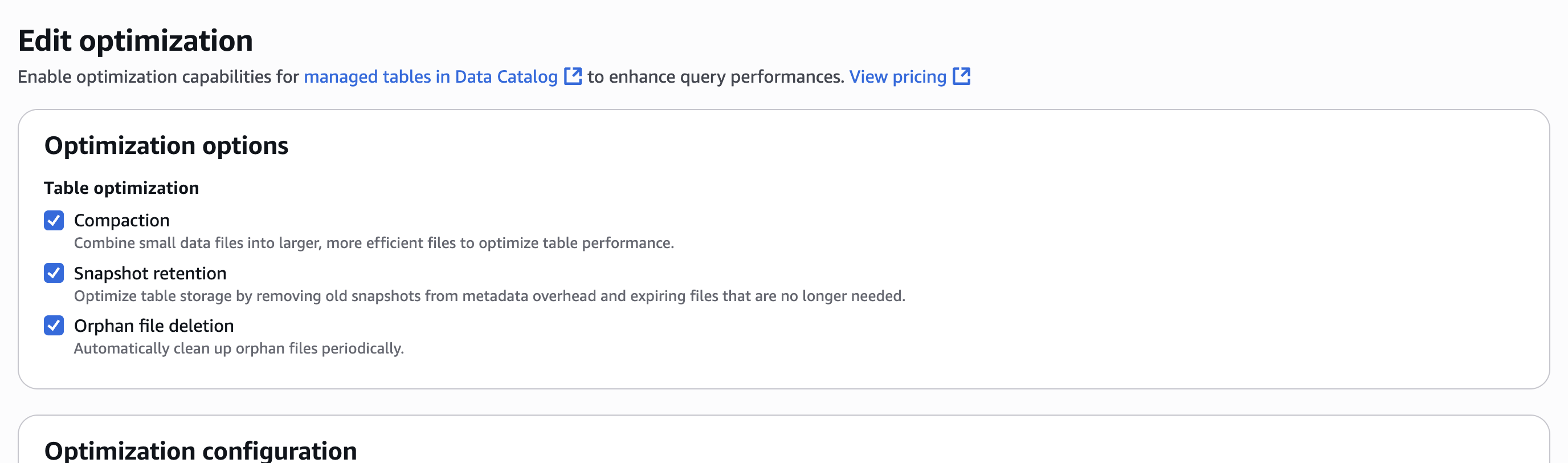
- Select an IAM role. Refer to Table optimization prerequisites for permissions.
- Choose Grant required permissions.
- Choose I acknowledge that expired data will be deleted as part of the optimizers.
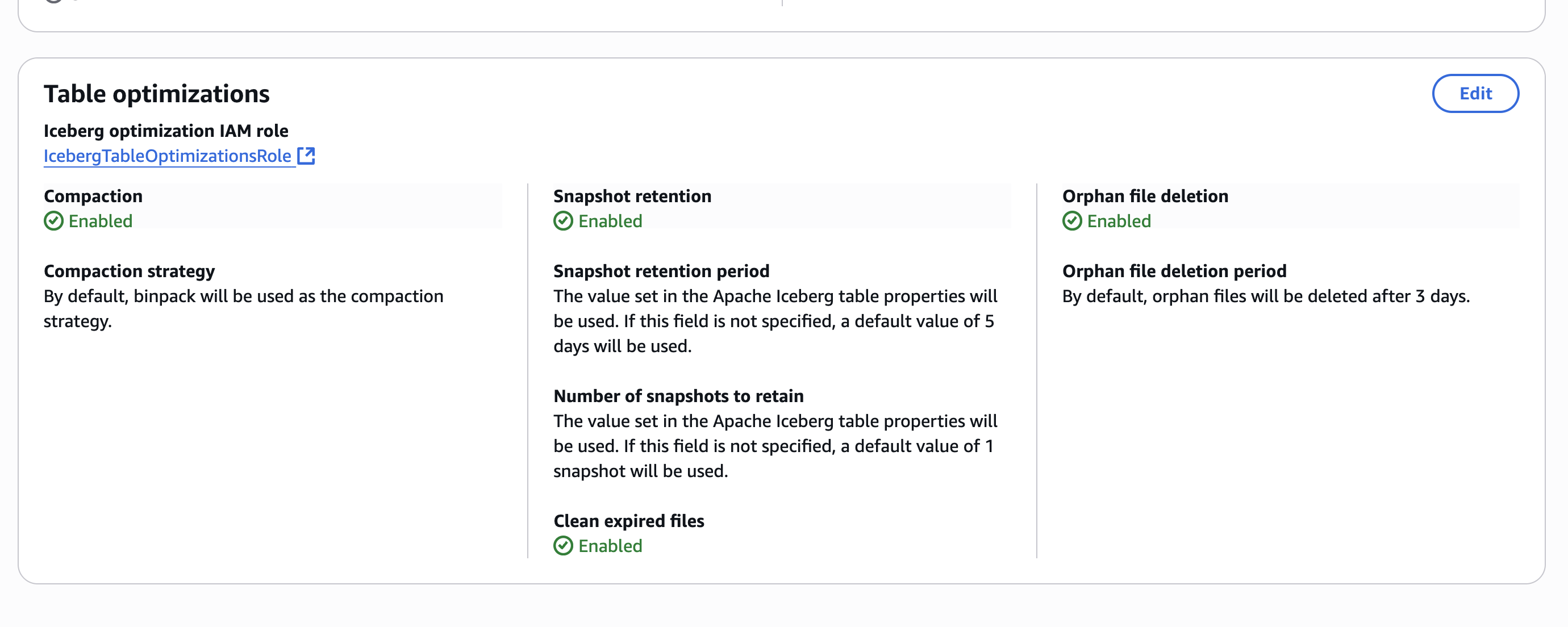
After you enable the table optimizations at the catalog level, the configuration is displayed on the AWS Lake Formation console, as shown in the following screenshot.
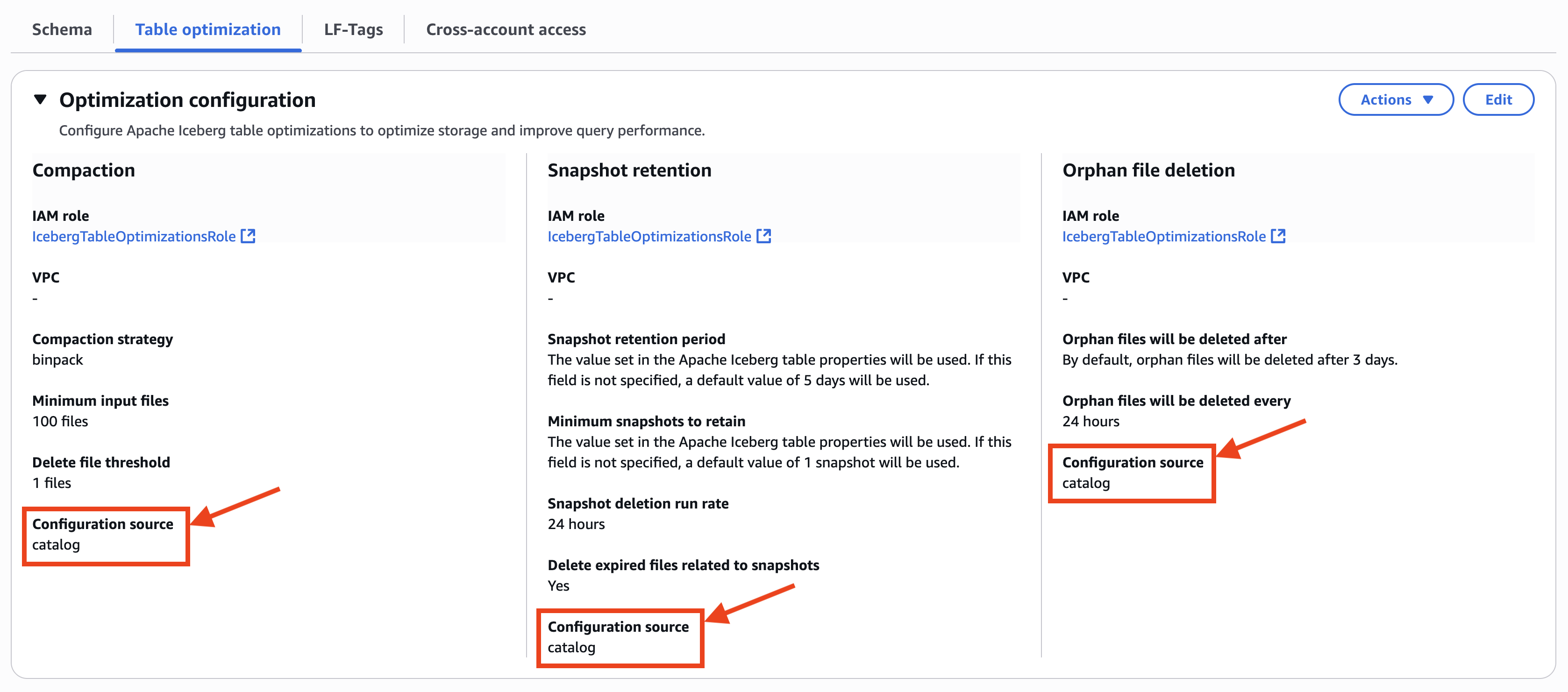
When you select an Iceberg table registered in the catalog, you can confirm that the table optimizations configuration is inherited from the table view because Configuration source shows catalog, as shown in the following screenshot.
The table optimizations history is displayed on the table view. The following result shows one of the compaction runs by the table optimizations.
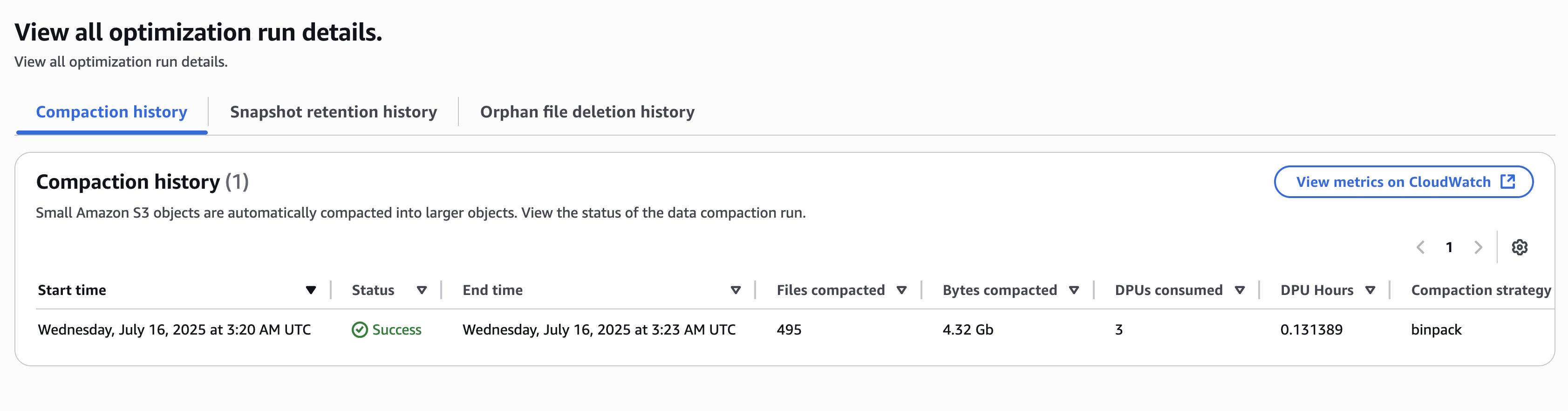
The catalog-level table optimizations for all databases and Iceberg tables are now enabled.
Customize setting of table optimizations at both the catalog and table-level
Although the catalog-level optimization applies common settings across all databases and Iceberg tables in your catalog, you might want to apply different strategies for specific Iceberg tables. You can use AWS Glue Data Catalog to enable both catalog-level and table-level optimizations based on specific table characteristics and access patterns. For example, in addition to configuring the catalog-level compaction with the bin-pack strategy for general-purpose Iceberg tables, you can apply the sort strategy at the table-level to tables with frequent range queries on timestamp columns.
This section shows configuring catalog-level and table-specific optimizations through a practical scenario. Imagine a real-time analytics table with frequent write operations that generates more orphan files due to constant metadata updates. Users also run selective queries filtering specific columns, which makes sort-order strategy preferable. Complete the following steps:
- Select another Iceberg table in the same catalog as before to configure the table-level optimizations on the AWS Lake Formation console. At this point, the catalog-level table optimizations are configured for this table.
- Choose Edit in Optimization configuration, as shown in the following screenshot.
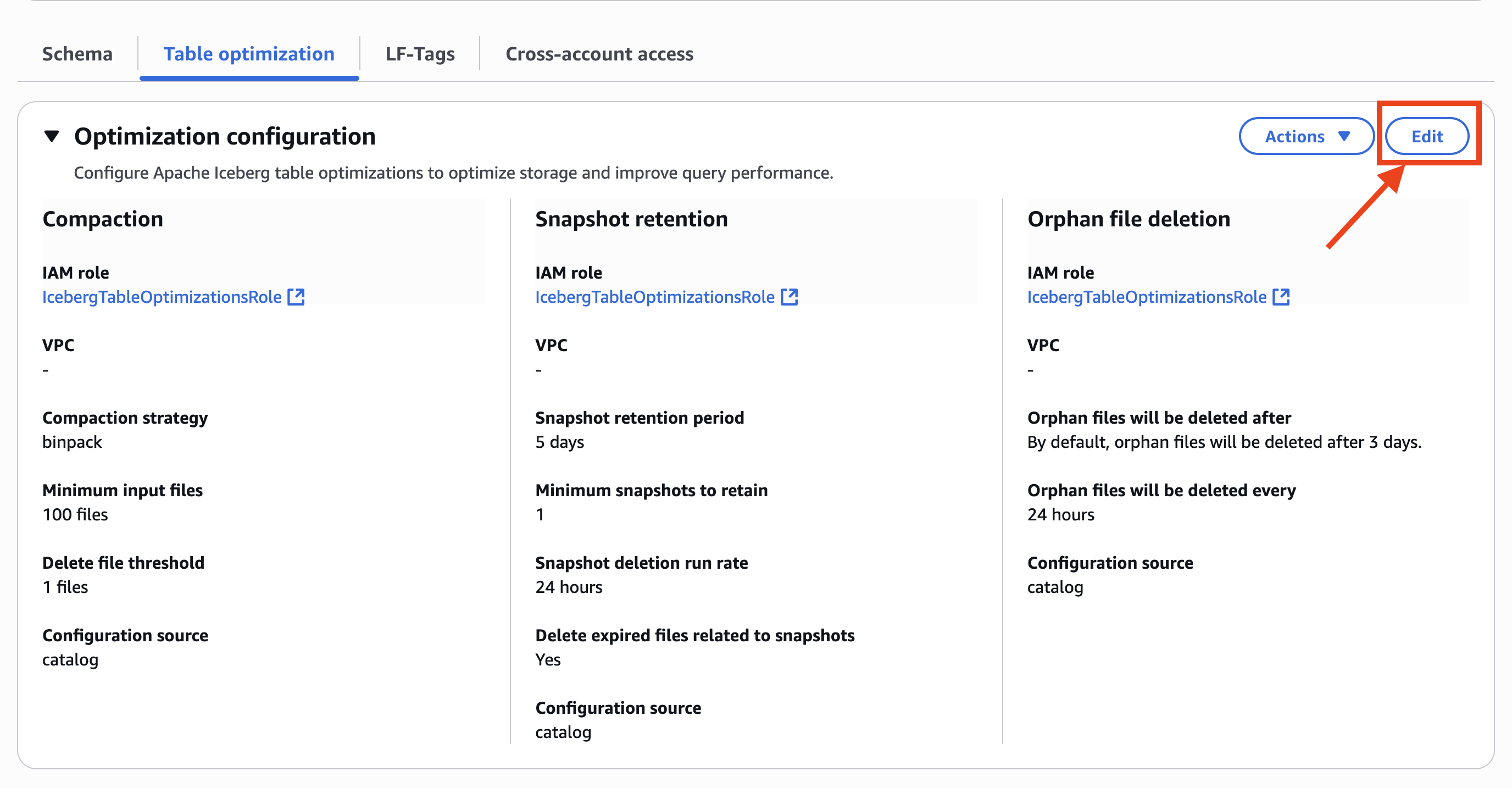
- In Optimization options, choose Compaction, Snapshot retention, and Orphan file deletion.
- In Optimization configuration, choose Customize settings.
- Select the same IAM role.
- In Compaction configuration, select Sort, as shown in the following screenshot. Also configure 80 files to Minimum input files, which is a threshold of the number of files to trigger the compaction. To configure Sort, a sort order needs to be defined in your Iceberg table. You can define the sort order with Spark SQL such as
ALTER TABLE db.tbl WRITE ORDERED BY.
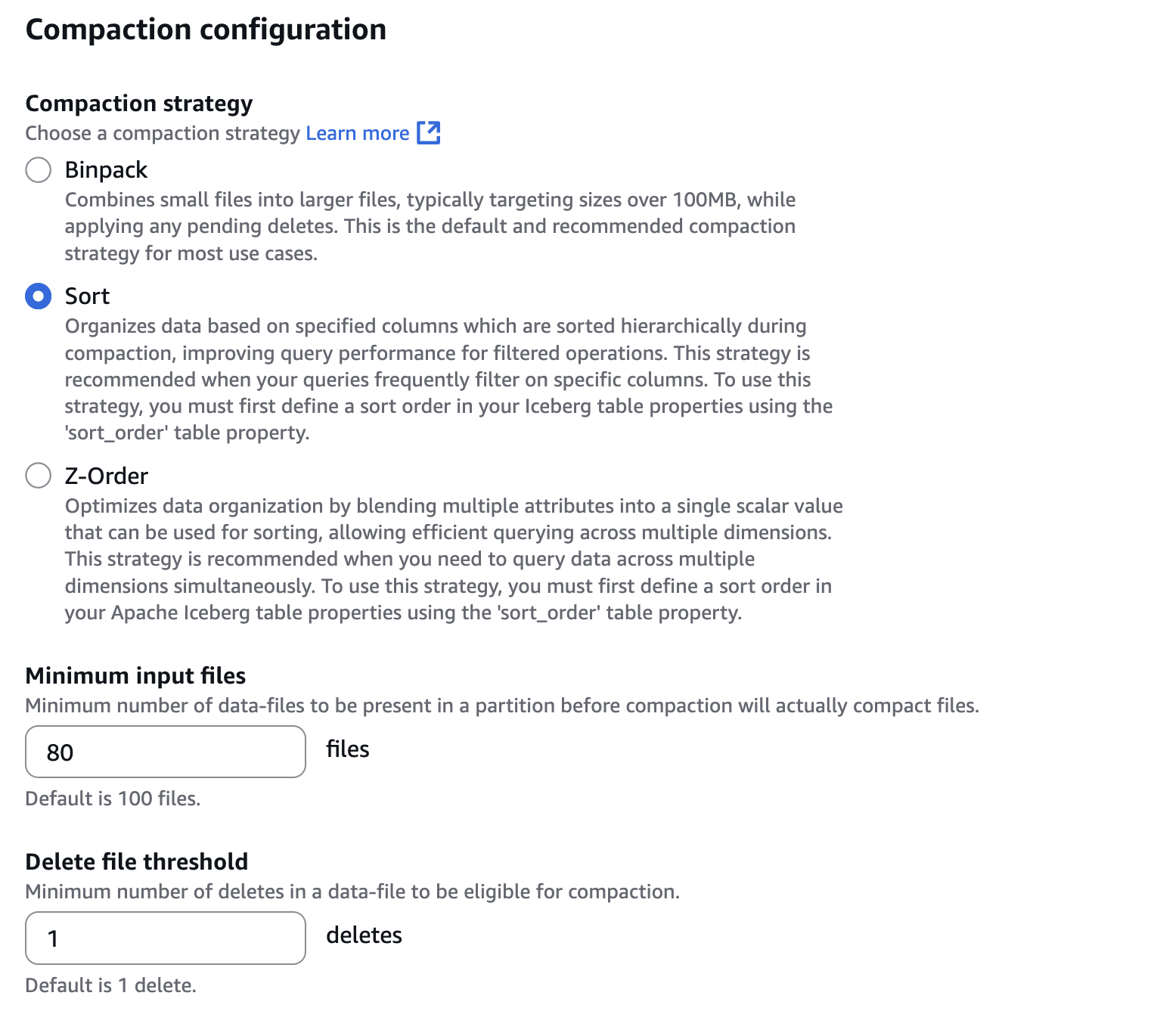
- In Snapshot retention configuration and Snapshot deletion run rate, select Specify a custom value in hours. Then, configure 12 hours to the interval between two deletion job runs, as shown in the following screenshot.

- In Orphan file deletion configuration, configure 1 day to Files under the provided Table Location with a creation time older than this number of days will be deleted if they are no longer referenced by the Apache Iceberg Table metadata.

- Choose Grant required permissions.
- Choose I acknowledge that expired data will be deleted as part of the optimizers.
- Choose Save.
- The Table optimization tab on the AWS Lake Formation console displays the custom setting of table optimizers. In Compaction, Compaction strategy is configured to sort and Minimum input files is also configured to 80 files. In Snapshot retention, Snapshot deletion run rate is configured to 12 hours. In Orphan file deletion, Orphan files will be deleted after is configured to 1 days, as shown in the following screenshot.
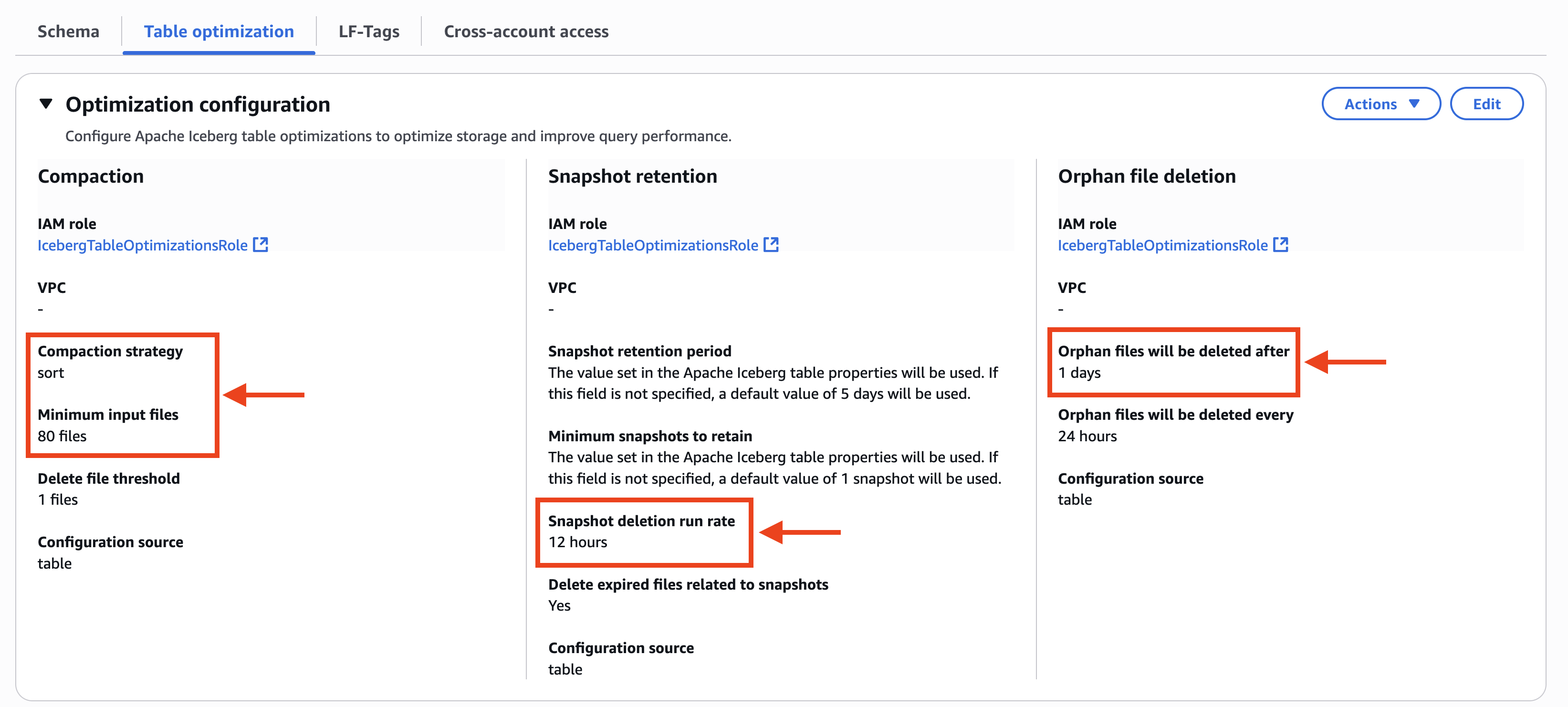
The compaction history shows sort as its table-level compaction strategy even if the strategy in the catalog-level is configured to binpack, as shown in the following screenshot.
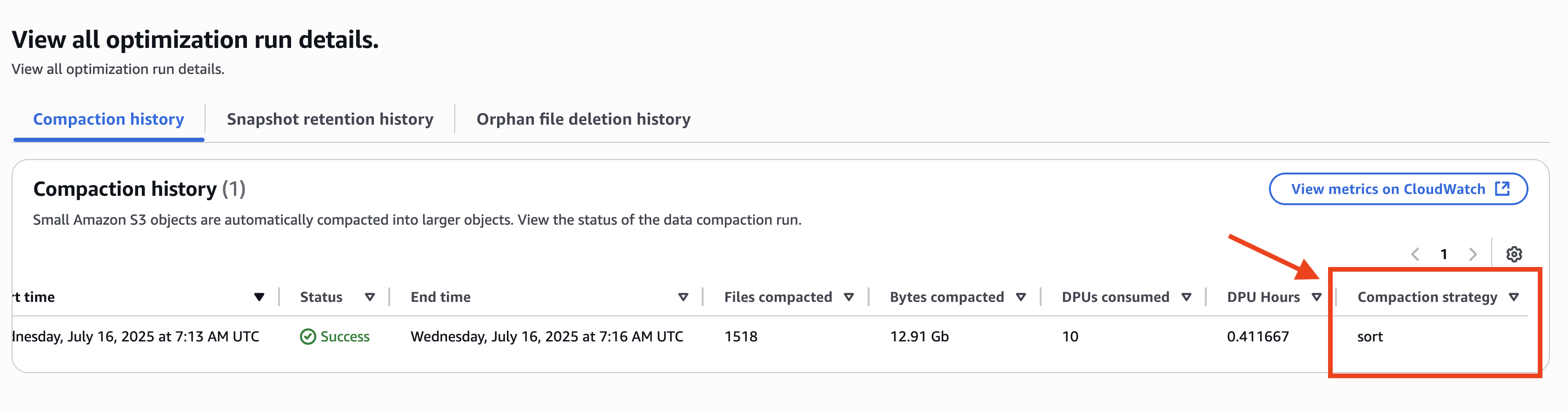
In this scenario, the table-specific optimizations are configured along with the catalog-level optimizations. Combining the table and catalog-level optimizations means you can more flexibly manage your Iceberg table data deletions and compactions.
Conclusion
In this post, we demonstrated how to enable and manage using Amazon SageMaker lakehouse architecture with AWS Glue Data Catalog’s catalog-level table optimization feature for Iceberg tables. This enhancement significantly simplifies the management of Iceberg tables because you can enable automated maintenance operations across all tables with a single setting. Instead of configuring optimization settings for individual tables, you can now maintain your entire data lake more efficiently, reducing operational overhead while ensuring consistent optimization policies. We recommend enabling catalog-level table optimization to help you maintain a well-organized, high-performing, and cost-effective data lake while freeing up your teams to focus on deriving value from your data.
Try out this feature for your own use case and share your feedback and questions in the comments. To learn more about AWS Glue Data Catalog table optimizer, visit Optimizing Iceberg tables.
Acknowledgment: A special thanks to everyone who contributed to the development and launch of catalog level optimization: Siddharth Padmanabhan Ramanarayanan, Dhrithi Chidananda, Noella Jiang, Sangeet Lohariwala, Shyam Rathi, Anuj Jigneshkumar Vakil, and Jeremy Song.
About the authors
 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
 Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
 Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
 Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.
Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.